Дизайн моніторингу мультикластерів Openshift
Опис
В дана статті описується можливий підхід для забезпечення централізованого моніторингу кластерів платформи управління реєстрами в залежності від їх розташування. В статті наведений перелік та опис програмного забезпечення, що може бути використано для створення централізованої системи моніторингу.
VictoriaMetrics
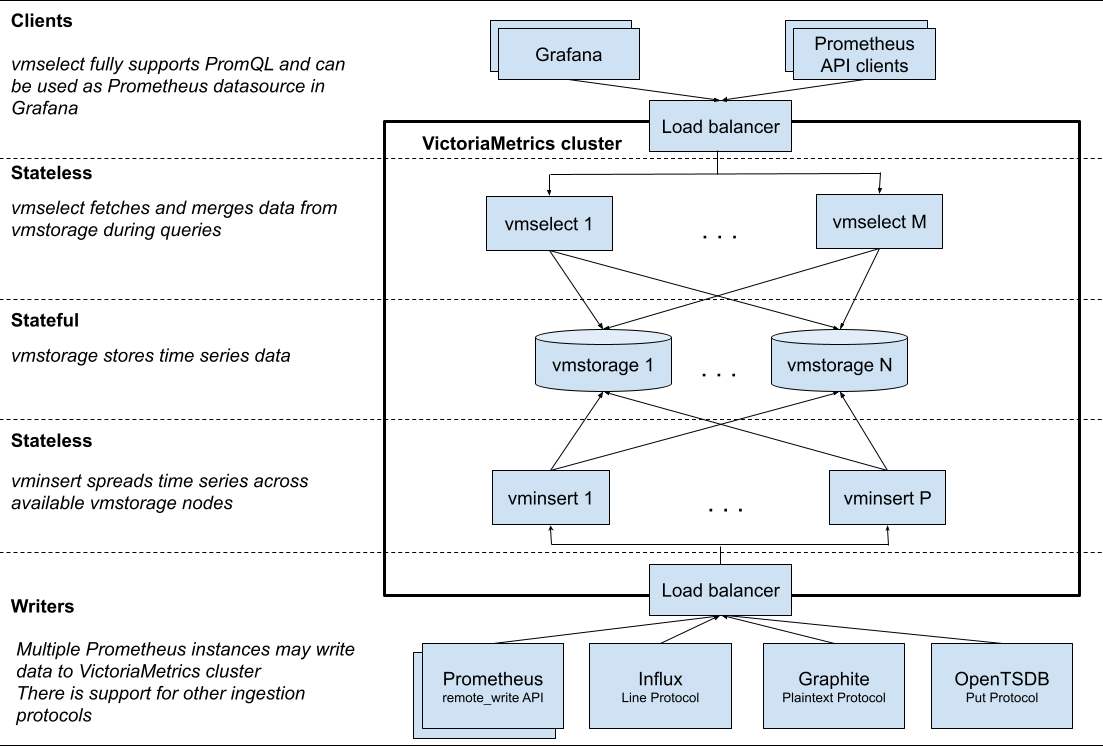
VictoriaMetrics являється time-series базою даних, що підтримує PromQL і навіть розширяє її. Вона може збирати дані з Prometheus інстансів використовуючи remote write API, а також з інших ресурсів, що використовують протоколи як InfluxDB, Graphite та інші. Для додаткової інформації можна ознайомитись з офіційною документацією.
Встановлення VictoriaMetrics
VictoriaMetrics може бути розгорнута за допомогою Docker Compose на окремому інстансі Ubuntu, з 8 GB RAM, 4 CPU cores, and 500GB disk.
Prometheus Operator setup
Prometheus на платформі Openshift керується Cluster Monitoring Operator та Prometheus Operator. Кастомізація OCP Prometheus дуже обмежена та виконується через cluster-monitoring-config ConfigMap.
Конфігурування є простим: відредагувати або створити cluster-monitoring-config ConfigMap. Додати externalLabels що будуть ідентифікувати кластер і визначити remoteWrite endpoint, в нашому випадку VictoriaMetrics TSDB.
apiVersion: v1
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
externalLabels:
cluster: labdev
type: dev
remoteWrite:
- url: "http://victoriametrics-url:8428/api/v1/write"
kind: ConfigMap
Дедуплікація/дублювання метрик
The Cluster Monitoring Operator в OpenShift створює дві Prometheus репліки для забезпечення HA і кожна з двух реплік містить однаковий сет метрик. Після того, як увімкнеться remoteWrite налаштування, кожна репліка буде сконфігурованою перенаправляти метрики в VictoriaMetrics. В загальному, VictoriaMetrics може відстежувати дублювання метрик., але це вимагає однаковий сет externalLabels для кожної репліки. Prometheus оператор внітрішньо додає додатковий лейбл для метрики з унікальним значенням для кожної репліки. На жаль, поведінка така поведінка не може бути змінена для Prometheus, що менеджиться OpenShift Cluster Monitoring Operator, але такий лейбл може бути видалений, використовуючи relabelConfig option, наступним чином:
- action: labeldrop regex: "prometheus_replica"
Grafana дашборди
Grafana отримує дані напряму від VictoriaMetrics API, яка сумісна з Prometheus query API.
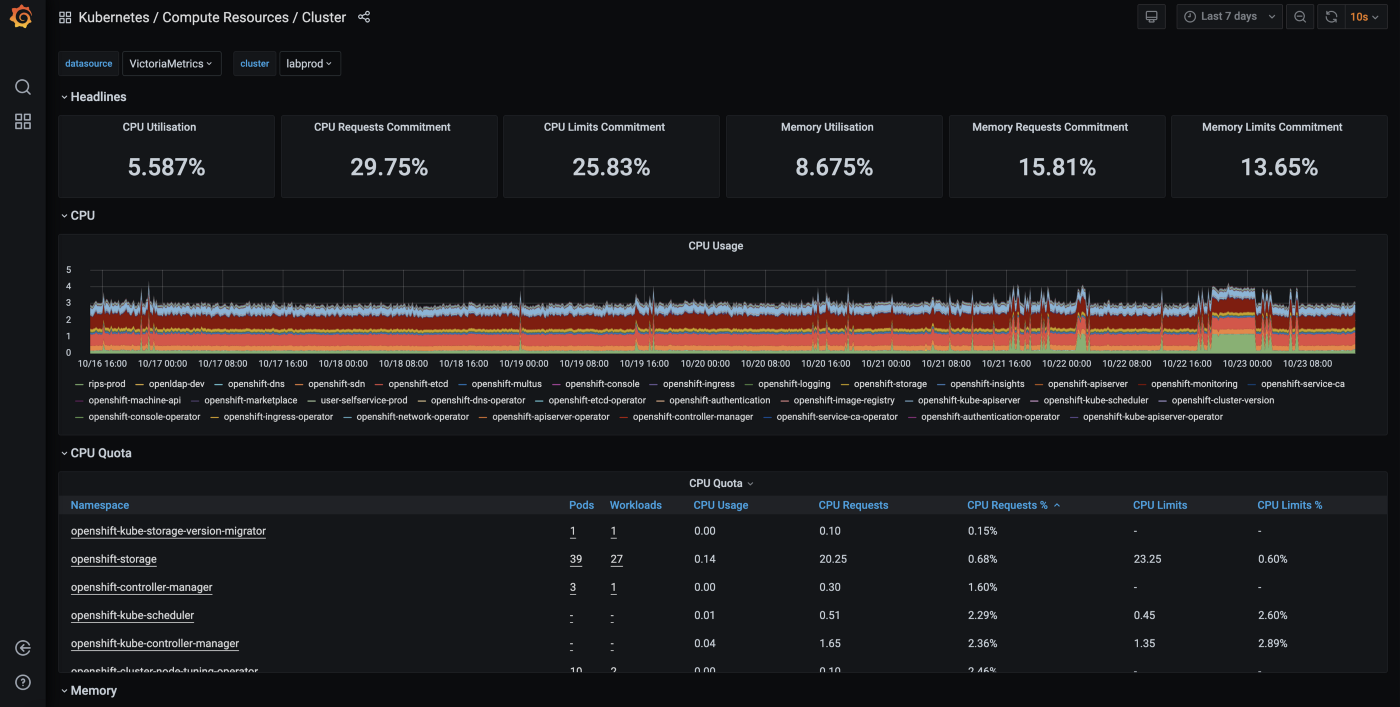
Openshift розгортається з кількома Grafana дашбордами, що можуть бути легко змінені для підтримки мультикластерів. Зовнішні лейби визначаються як додаткове Prometheus Operator налаштування і добавляє лейбл до кожної метрики, що перенаправляється до VictoriaMetrics. Можна використовувати додаткові темплейт змінні в дашборді і фільтри. Приклади можна переглянути тут.
Високорівневий дизайн централізованої системи моніторингу
Нижче описано три можливих сценарія розгортання та налаштування централізованого кластеру моніторингу та комунікації його з цільовими кластерами платформи управління реєстрами.
Сценарій 1
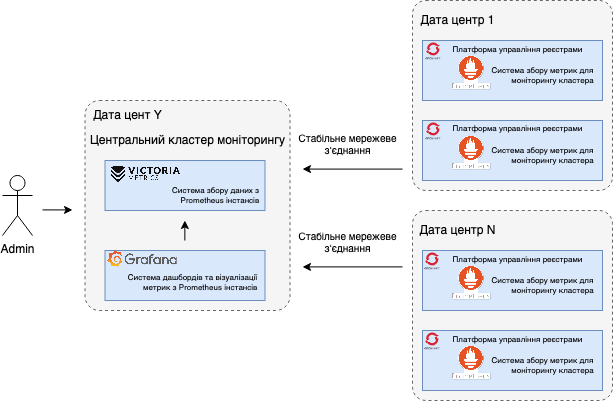
Сценарій 1 відображає централізовану систему моніторингу в дата-центрі відмінному від дата-центрів, де розташовані цільові кластери платформ управління реєстрами. При такому сценарії необхідним є забезпечити стабільний мережевий зв‘язок між дата-центром цільового кластеру платформи управління реєстрами та дата-центром централізованої системи моніторингу.
Сценарій 2
Поточний сценарій 2 показує таку ж централізовану систему моніторингу як сценарій 1, в умовах розташування цільових кластерів платформи управління реєстрами в різних дата-центрах. Його відмінністю є конфігурація в режимі High Available кластера: дві ідентичні копії, що синхронізуються між собою, знаходяться в різних дата-центра. Це обумовлює доступність моніторингової системи в випадку виникнення проблем з одним з дата-центрів моніторингової системи.
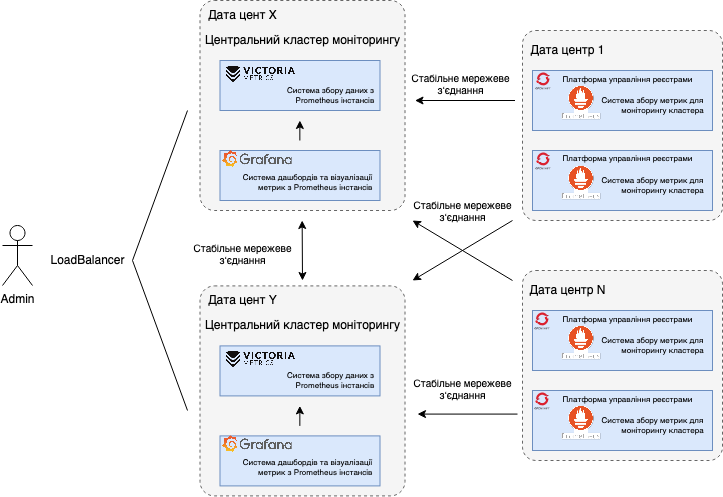
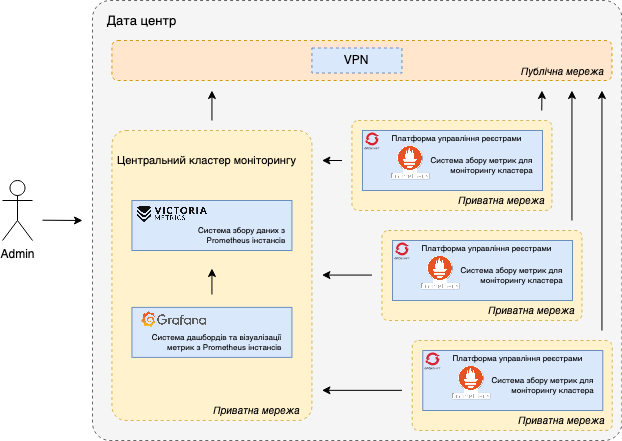
Сценарій 3
Сценарій 3 відображає централізовану систему моніторингу в умовах одного дата-центру. Така конфігурація може бути обумовлена розгортанням кластера платформи управління реєстрами в закритому периметрі, що має обмежений доступ до зовнішніх ресурсів.