Оновлення Платформи та реєстрів до версії 1.9.5: спеціальні кроки
- 1. Мета інструкції
- 2. Підготовка кластера Платформи до оновлення
- 3. Оновлення Платформи
- 4. Кроки після оновлення Платформи
- 5. Оновлення реєстру
- 6. Кроки після оновлення реєстру
- 7. Відомі проблеми
- 8. Специфічні та нечасті помилки
- 9. Зворотно несумісні зміни
1. Мета інструкції
Метою цієї сторінки є відображення процесу оновлення та спеціальних кроків, необхідних для оновлення кластера Платформи та реєстрів з версії 1.9.4.31 до 1.9.5.19.
Послідовність процесу оновлення:
Додатково зверніть увагу на:
2. Підготовка кластера Платформи до оновлення
2.1. Підготовка кластерів, розгорнутих на vSphere
-
Зробіть резервні копії платформних компонентів Vault та Minio разом із томами (volumes) за допомогою vSphere.
Приклади знімків (snapshots)
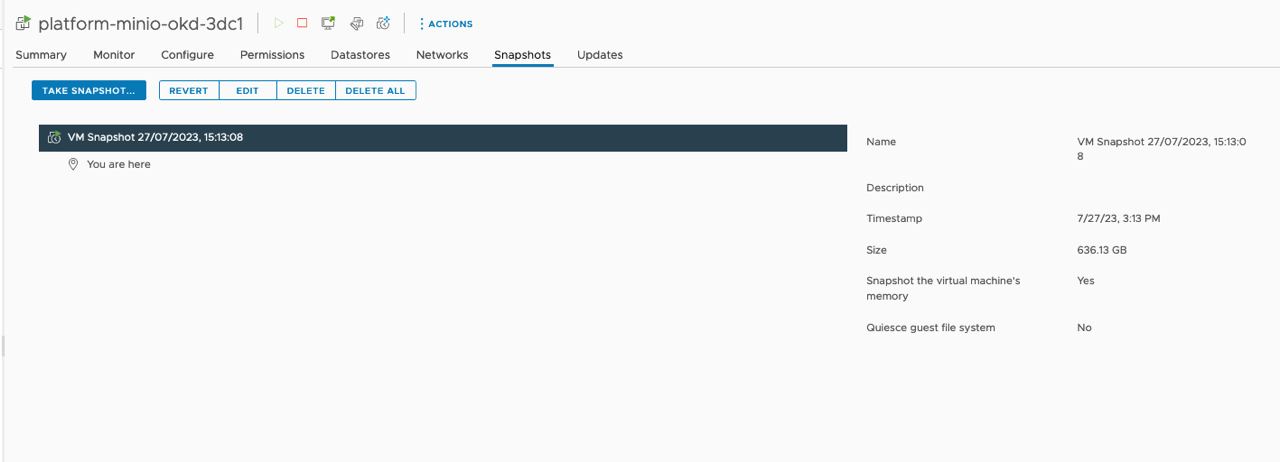
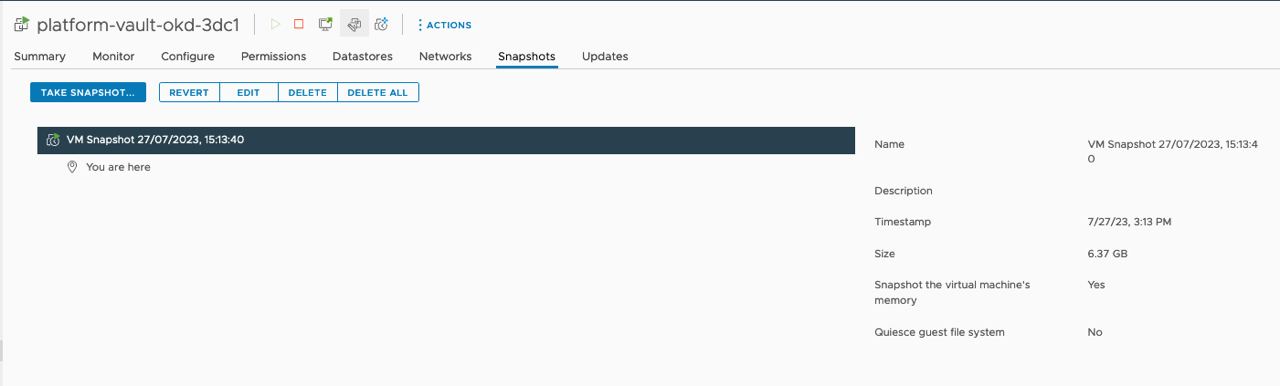
-
В інтерфейсі vSphere створіть нову папку для перенесення томів Minio поряд зі старою папкою.
-
В інтерфейсі vSphere від’єднайте том Minio та перенесіть його зі старої в нову папку, створену на попередньому кроці (2).
-
В інтерфейсі vSphere видаліть екземпляр Minio.
-
Після перенесення станів Terraform з релізу
1.9.4на1.9.5, видаліть зі стану Minio ресурсvsphere_virtual_machine.vmу папці terraform/minio/vsphere розпакованої Платформи 1.9.5 за допомогою наступної команди:$ terraform state rm vsphere_virtual_machine.vm
3. Оновлення Платформи
3.1. Запуск пайплайну platform-deploy
Запустіть пайплайн platform-deploy в Jenkins CICD2 з опціями оновлення та необхідною версією збірки, а саме 1.9.5.19.
Вкажіть необхідний режим розгортання (deploymentMode).
3.2. Оновлення cluster-mgmt
Цей крок описує стандартний процес оновлення інфраструктурних компонентів Платформи за допомогою пайплайну cluster-mgmt в адміністративній панелі Control Plane.
| Див. детальніше на сторінці Оновлення інфраструктурних компонентів Платформи. |
4. Кроки після оновлення Платформи
4.1. Кроки для кластерів, розгорнутих на vSphere
-
В інтерфейсі vSphere під’єднайте старий том до екземпляру Minio.
-
На jump-хості[1]. у папці розпакованої Платформи
1.9.5terraform/minio/vsphere/packer перейдіть на екземпляр Minio за допомогою SSH-з’єднання.$ cd terraform/minio/vsphere/packer $ ssh -i private.key mdtuddm@0.0.0.0 # змініть 0.0.0.0 на IP MinioВідновіть дані зі старого тому на новий, виконавши наступні команди:
$ sudo su $ mkdir -p /usr/local/share/minio-backup $ lsblk # тут треба переконатися, що новий том знаходиться за шляхом /dev/sdc $ echo "/dev/sdc /usr/local/share/minio-backup ext4 defaults 0 0" | tee -a /etc/fstab >/dev/null $ mount /usr/local/share/minio-backup $ systemctl stop minio $ cp -R /usr/local/share/minio-backup/mdtuddm/* /usr/local/share/minio/storage/mdtuddm/ $ chown -R minio:minio /usr/local/share/minio $ systemctl start minio $ systemctl status minio $ umount /usr/local/share/minio-backup $ sed -i '$ d' /etc/fstab $ rm -rf usr/local/share/minio-backup -
В інтерфейсі Minio перевірте наявність даних, перенесених на попередньому кроці (2).
-
В інтерфейсі vSphere від’єднайте старий том від екземпляра Minio.
4.2. Оновлення екземплярів для машин-сетів Ceph та Logging
| Розділ стосується лише кластерів, розгорнутих у середовищі AWS. |
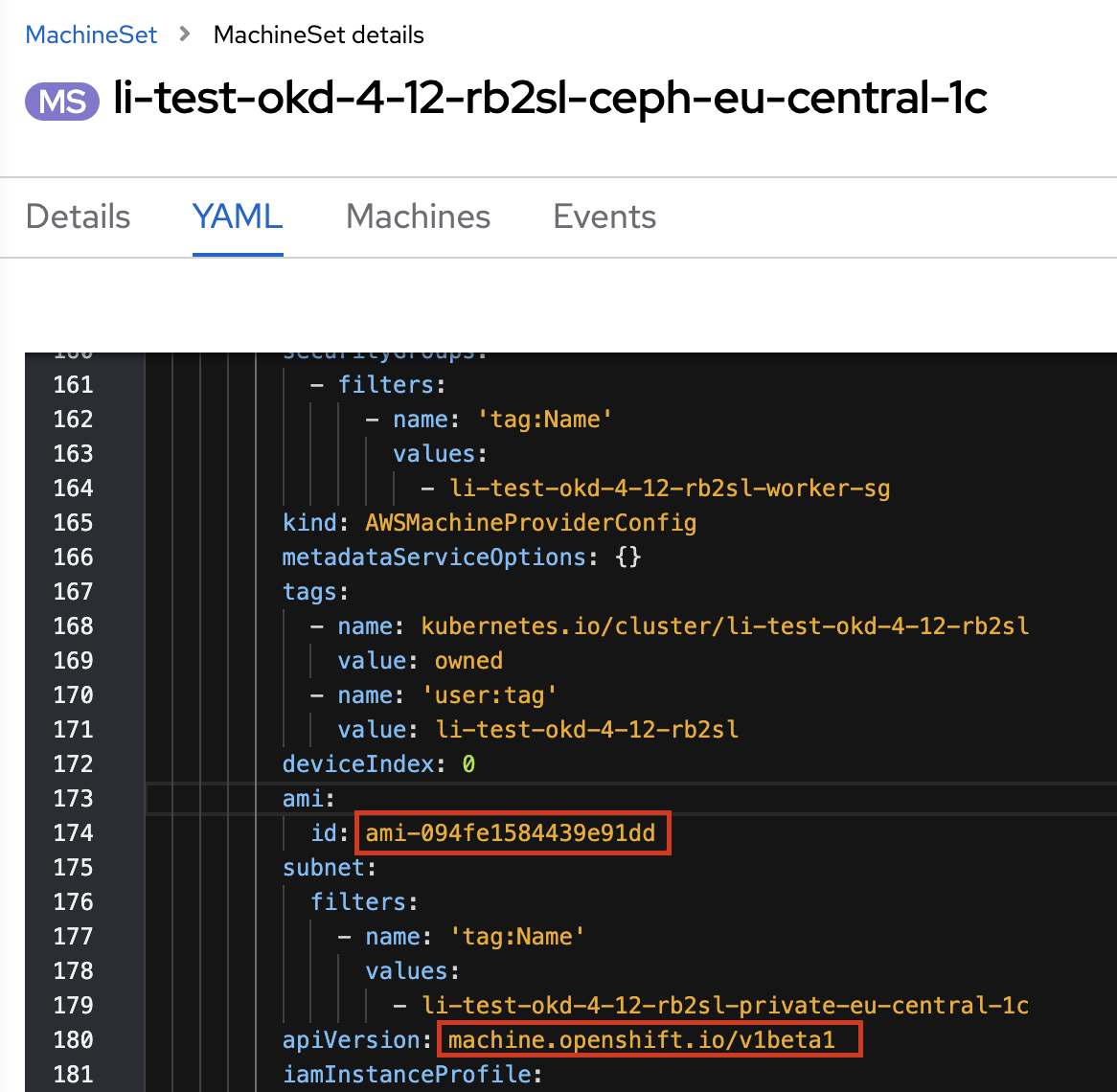
4.2.1. Перевірка полів для машин-сетів Ceph та Logging
Після успішного запуску задачі cluster-mgmt, перевірте, що у машин-сети (machine sets) ceph та logging мають наступні значення полів ami.id та apiVersion:
-
ami.id:ami-094fe1584439e91dd -
apiVersion:machine.openshift.io/v1beta1
4.2.2. Видалення машин для машин-сетів Ceph та Logging
Щоби нові поля застосувалися для всіх екземплярів машин-сету, потрібно поступово, по одній, видаляти машини поточного машин-сету через інтерфейс OpenShift.
| Цей процес потрібно повторити для всіх машин, які належать до машин-сетів Ceph та Logging. |
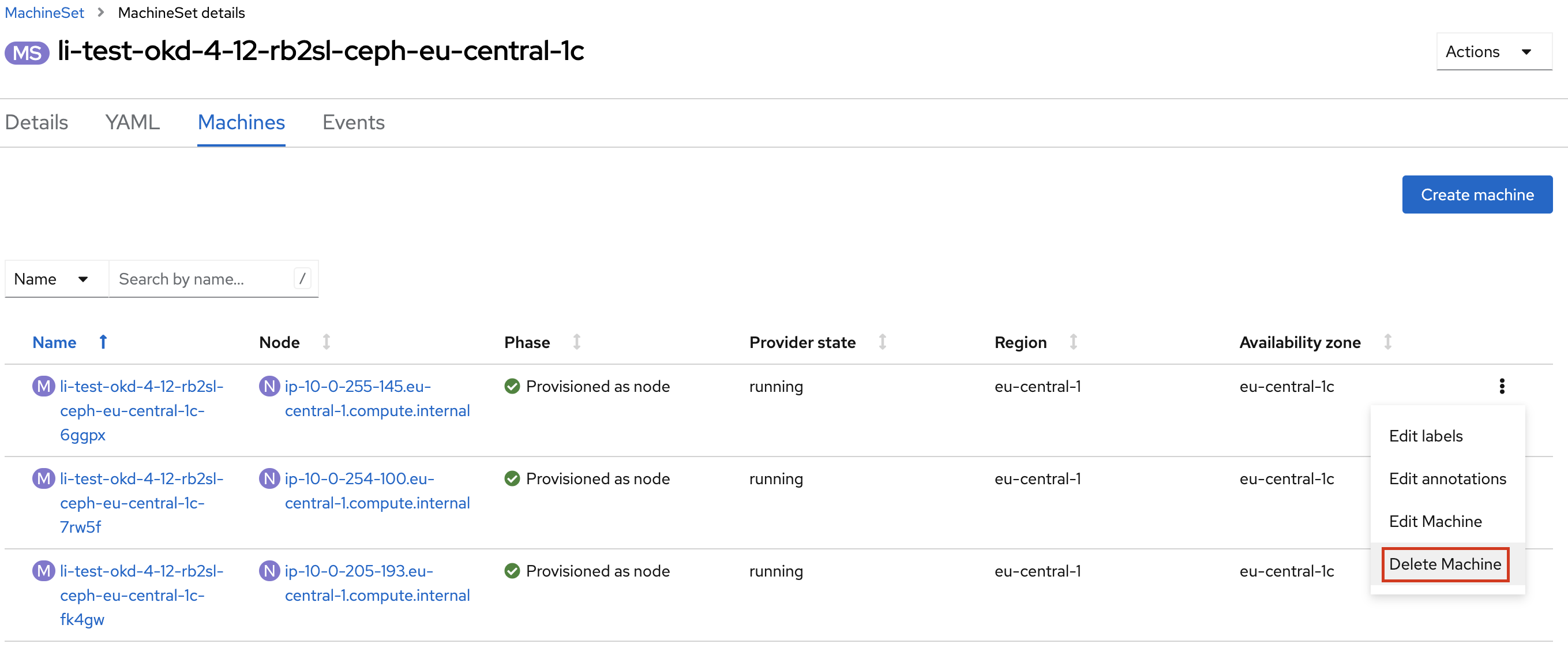
cephПісля видалення машини, нова запуститься автоматично, але вже із новими значеннями полів ami.id та apiVersion.
| Зачекайте, доки запуститься нова машина, і лише після цього переходьте до видалення іншої. |
Після того, як всі машини для машин-сетів Ceph та Logging будуть перестворені з новими полями ami.id та apiVersion, крок "Оновлення екземплярів для машин-сетів Ceph та Logging" вважається завершеним.
4.3. Оновлення екземплярів для робочих нод кластера
Після оновлення інстансів для машин-сетів Ceph та Logging, оновіть інстанси для робочих нод кластера.
4.3.1. Налаштування полів для робочих нод
Перейдіть до машин-сету робочих нод та змініть значення полів ami.id та apiVersion на наступні:
-
ami.id:ami-094fe1584439e91dd -
apiVersion:machine.openshift.io/v1beta1
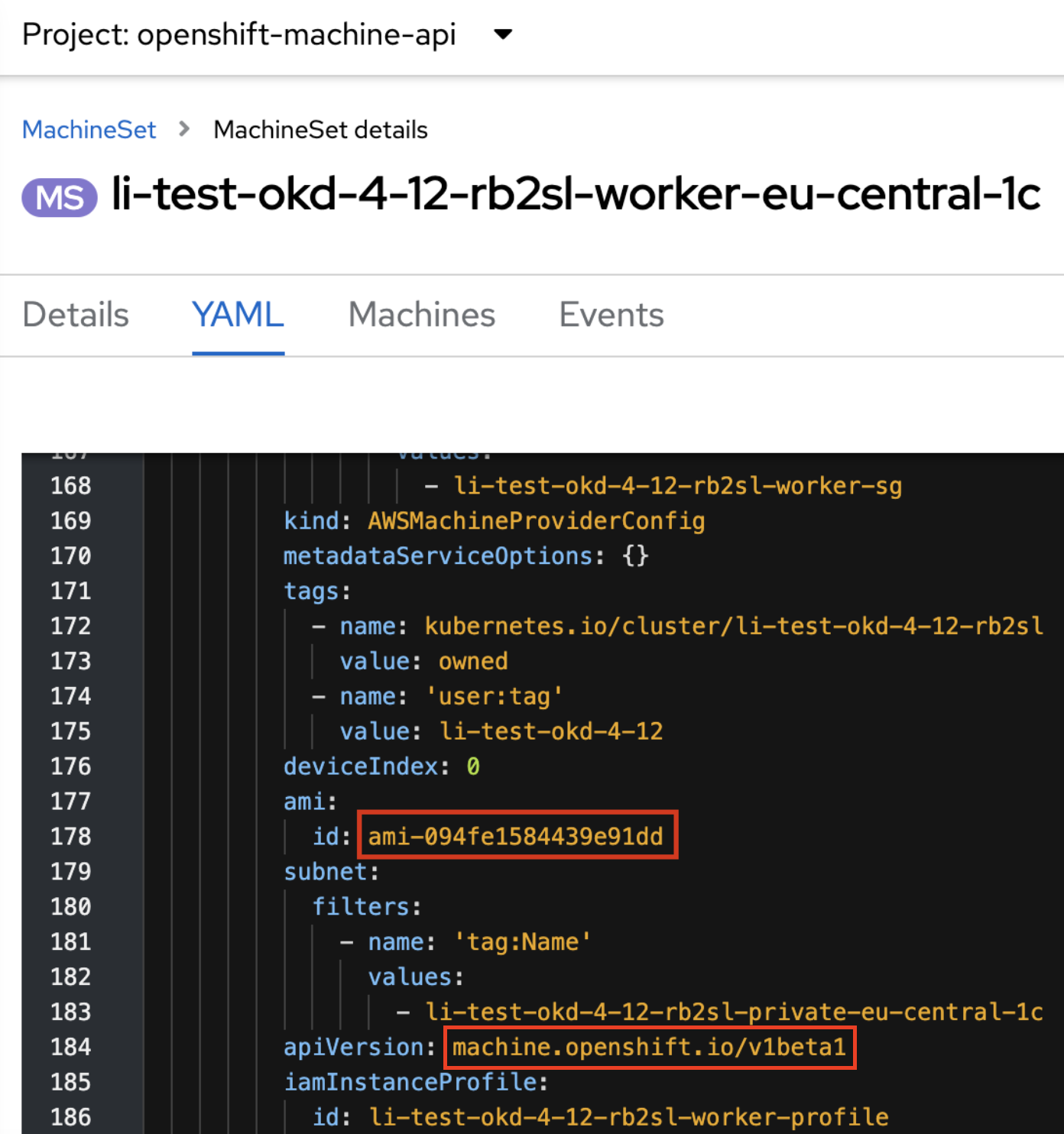
ami.id та apiVersion для робочих нод4.3.2. Видалення машин для машин-сетів робочих нод
Щоб нове поле застосувалося для всіх екземплярів машин-сету, потрібно поступово, по одній, видаляти машини поточного машин-сету.
Машини, що належать до набору machine set робочих нод кластера, часто мають проблеми із видаленням. Щоб уникнути цього, перед видаленням машини потрібно виконати деякі команди через термінал.
Для видалення машини виконайте наступні кроки:
-
Увійдіть до цільового кластера через термінал:


-
У машин-сеті, який належить до робочих нод кластера, оберіть одну машину, яку плануєте видалити, та скопіюйте назву ноди.
У цьому прикладі назва —
ip-10-0-198-21.eu-central-1.compute.internal.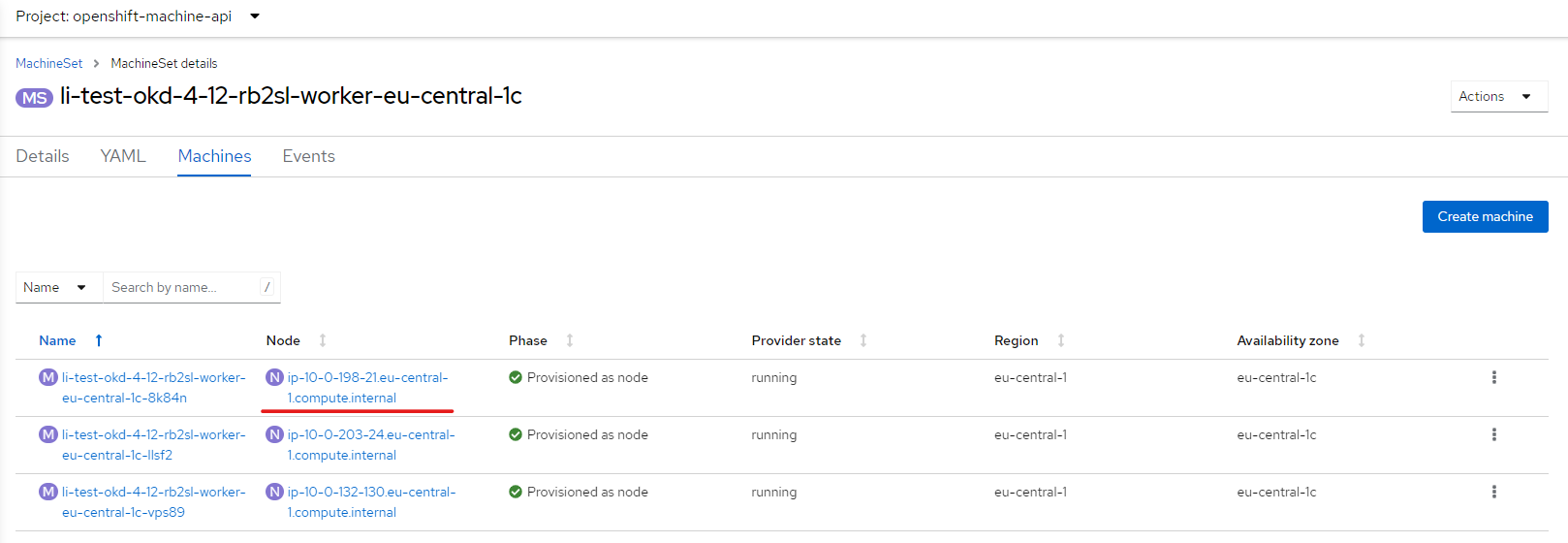
-
Виконайте наступні команди у терміналі, підставивши скопійоване ім’я ноди:
$ oc adm cordon ip-10-0-198-21.eu-central-1.compute.internal $ oc adm drain ip-10-0-198-21.eu-central-1.compute.internal --ignore-daemonsets --delete-emptydir-dataМоже статися, що команда
oc adm drainпісля виконання видасть помилку з подамиistiodабоistioingressgateway.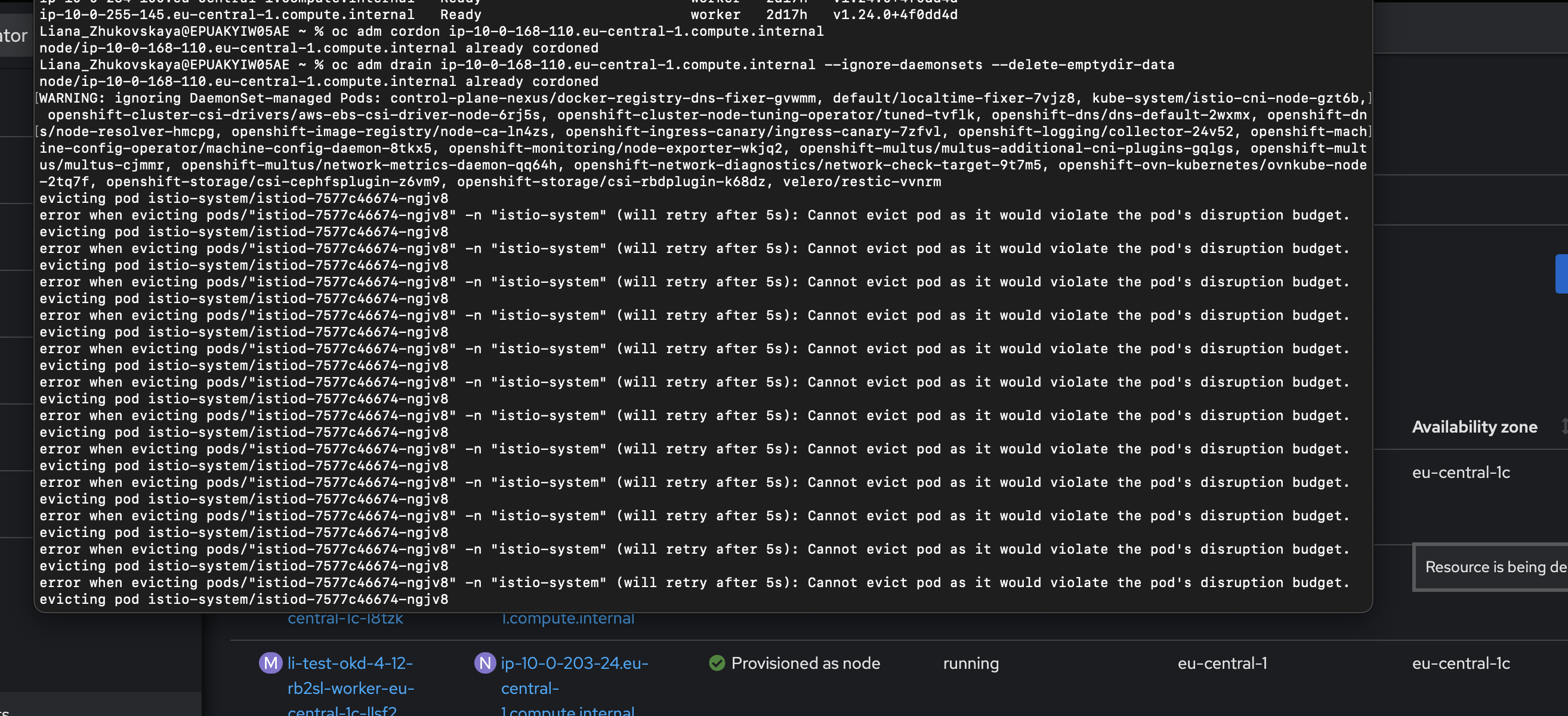 Зображення 4. Приклад помилки istio-system
Зображення 4. Приклад помилки istio-systemВ такому випадку потрібно в OpenShift перейти на ноду, для якої виконуються команди
oc adm, та знайти под, та знайти под, через який виникає конфлікт при виконанні командиoc adm drain. Цей под необхідно видалити. -
Після успішного виконання команд у терміналі, можна приступати до видалення машини безпосередньо через інтерфейс OpenShift.
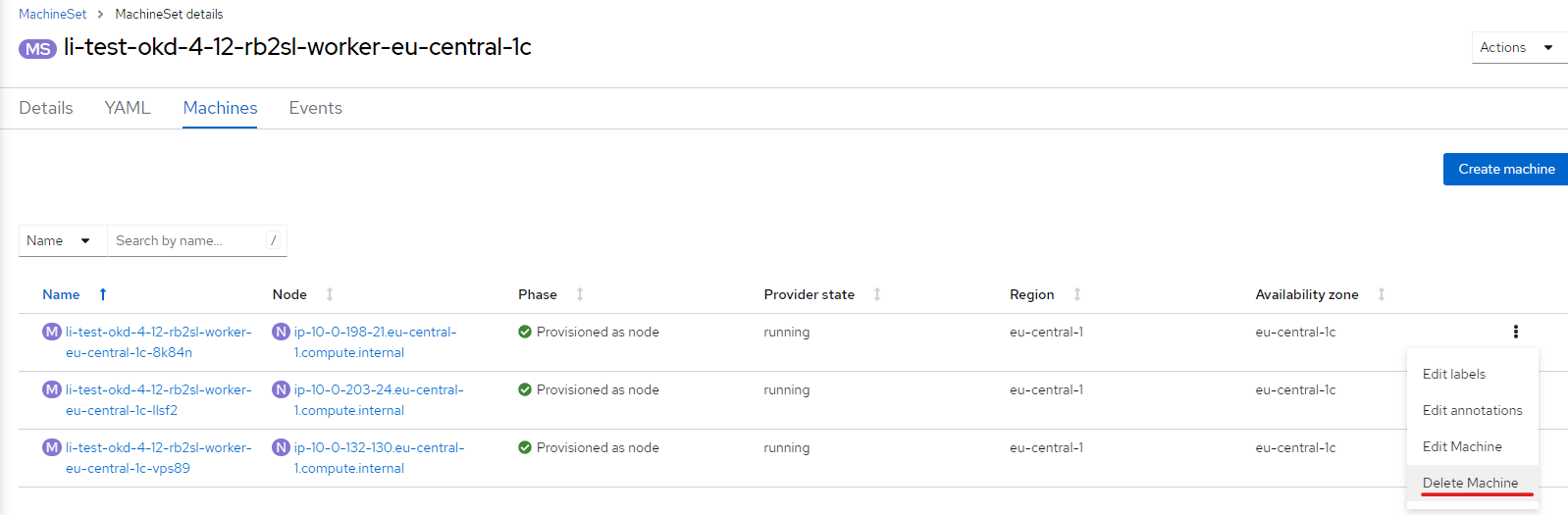 Зображення 5. Приклад видалення машини в інтерфейсі OpenShift
Зображення 5. Приклад видалення машини в інтерфейсі OpenShiftПісля того, як всі машини для машин-сету робочих нод кластера будуть перестворені з новим полем
ami.id, крок "Оновлення екземплярів для робочих нод кластера" вважається завершеним.
4.4. Виправлення помилок для коректної роботи пайплайнів по резервному копіюванню та відновленню з резервної копії
-
Видаліть файл з репозиторію
nexus.-
Перейдіть в центральний Gerrit та знайдіть репозиторій
components/registry/nexusза допомогою менюBROWSE.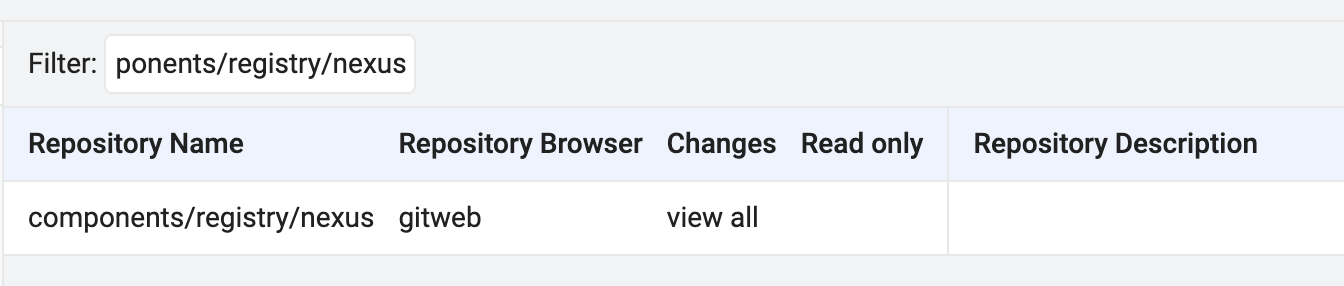
-
Відкрийте репозиторій та через бокову панель перейдіть в
Commands(1) >Create Change(2). У полі Select branch for new change введіть версію —1.5.0-SNAPSHOT.72(3), в полі Description введіть опис змін —Delete keycloakrolebatch(4). НатиснітьCreate.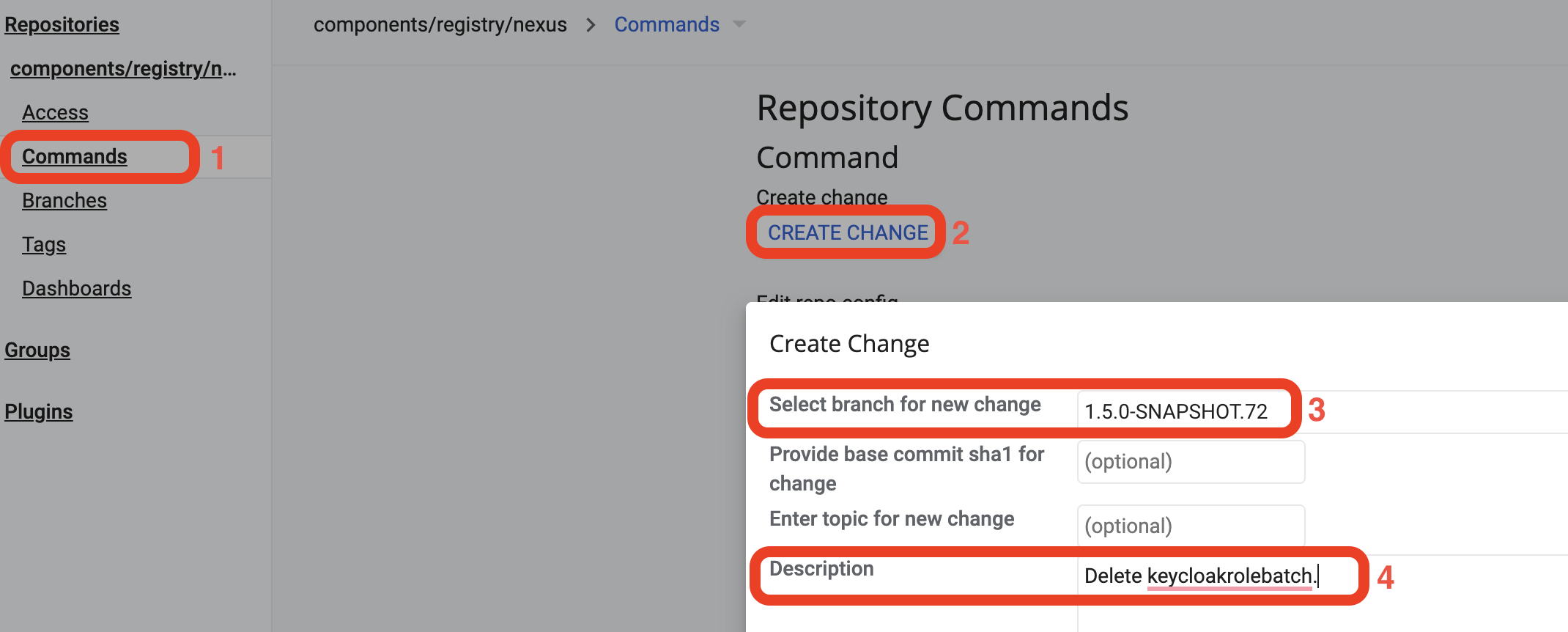
-
У відкритому Merge Request натисніть
Edit>Delete, у текстовому полі виберіть файл deploy-templates/templates/nexus-keycloak-roles.yaml та натиснітьDelete. Merge Request має виглядати як на зображенні: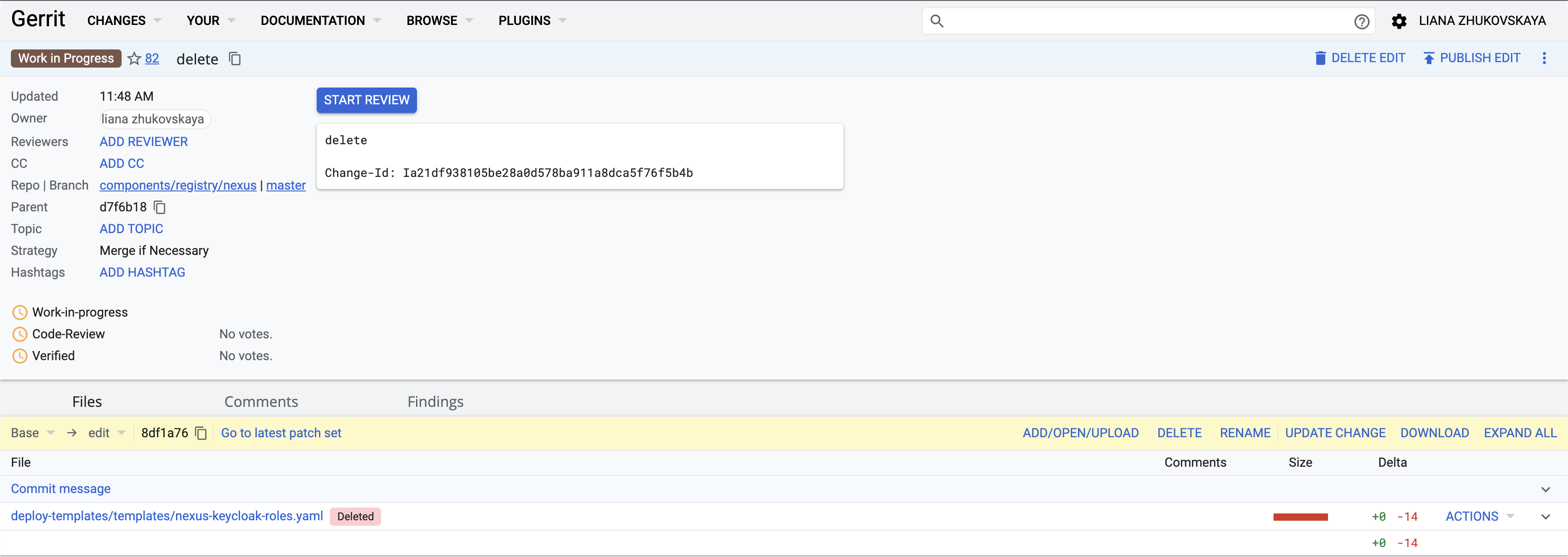
-
Після цього треба зробити
ReplyтаVerified +1,Code-Review +2,Submit.
-
-
Модифікуйте файл в репозиторії
backup-management.-
Перейдіть в центральний Gerrit та знайдіть репозиторій
components/infra/backup-managementза допомогою менюBROWSE.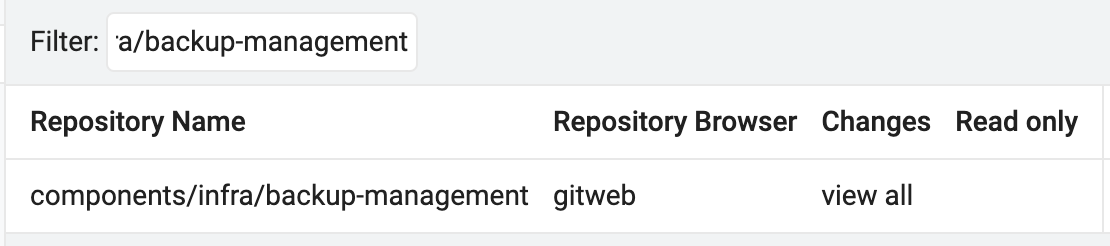
-
Відкрийте репозиторій та через бокову панель перейдіть в
Commands(1) >Create Change(2). В полі Select branch for new change введіть версію —1.9.4.10(3), в полі Description введіть опис змін —Modify configmap(4). НатиснітьCreate.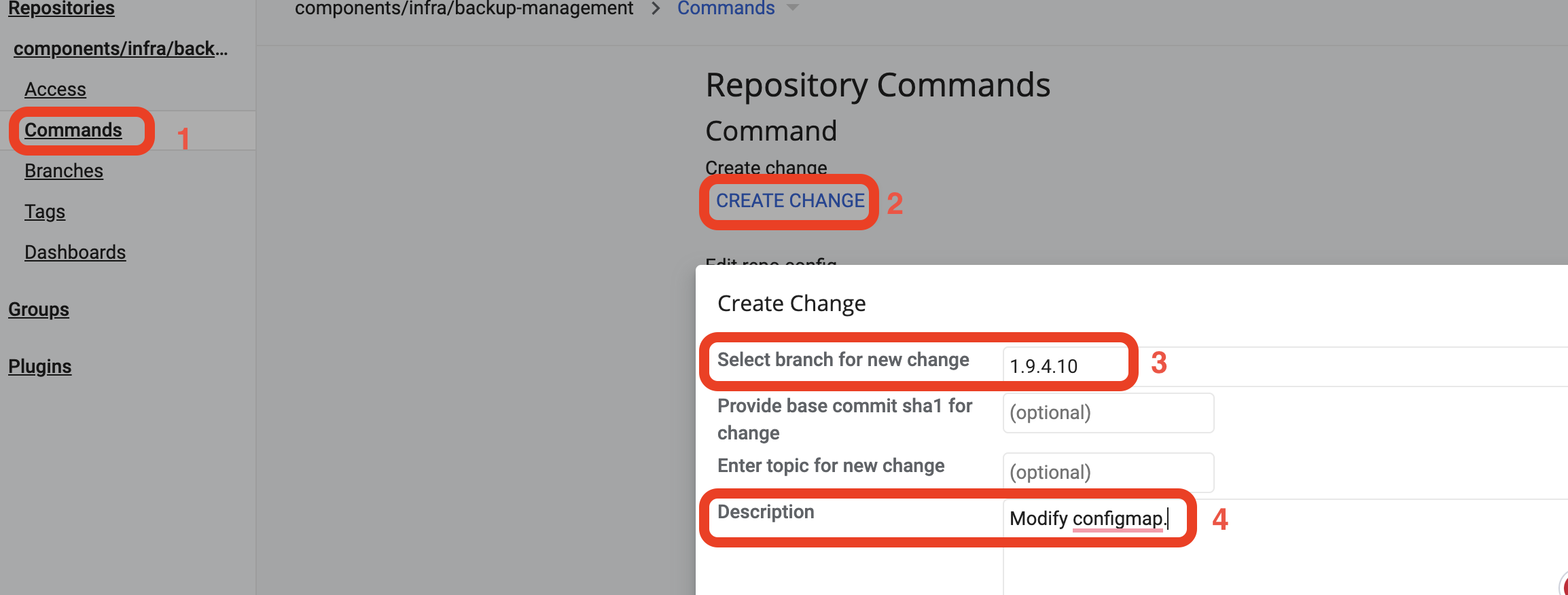
-
У відкритому Merge Request натисніть
Edit>ADD/OPEN/UPLOAD, в текстовому полі виберіть файл bucket-replication/templates/configmap.yaml та натиснітьConfirm.Далі видалити зміст файлу (Сtrl/command + A > Delete) та скопіюйте наступний код:
configmap.yaml
apiVersion: v1 kind: ConfigMap metadata: name: {{ include "bucket-replication.fullname" . }} namespace: {{ .Release.Namespace }} labels: {{- include "bucket-replication.labels" . | nindent 4 }} data: bucket-replication.sh: | #!/usr/bin/env bash rook_s3_endpoint=$(oc get cephobjectstore/mdtuddm -n openshift-storage -o=jsonpath='{.status.info.endpoint}') bucket=$(oc get objectbucketclaim/"${OBJECT_BUCKET_CLAIM}" -n ${REGISTRY_NAMESPACE} -o=jsonpath="{.spec.bucketName}") access_key_rook=$(oc get secret/"${OBJECT_BUCKET_CLAIM}" -n "${REGISTRY_NAMESPACE}" -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d) access_secret_key_rook=$(oc get secret/"${OBJECT_BUCKET_CLAIM}" -n "${REGISTRY_NAMESPACE}" -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d) mkdir -p ~/.config/rclone echo " ["${BACKUP_BUCKET}"] type = s3 provider = Other endpoint = ${S3_ENDPOINT} env_auth = true region = eu-central-1 acl = private bucket_acl = private [rook] type = s3 provider = Ceph env_auth = false access_key_id = ${access_key_rook} secret_access_key = ${access_secret_key_rook} endpoint = ${rook_s3_endpoint} acl = bucket-owner-full-control bucket_acl = authenticated-read" > ~/.config/rclone/rclone.conf # append only bucket - data bucket strategy (by label) - copy / other sync {{- if eq .Values.registryBackup.obc.action "replication" }} rclone_command="rclone copy -P --no-traverse --metadata" if [[ -z $(rclone lsd ${BACKUP_BUCKET}:${BACKUP_BUCKET}/obc-backups/${REGISTRY_NAMESPACE} | grep ${OBJECT_BUCKET_CLAIM}) ]]; then echo "[INFO] Destination folder empty, copy full bucket to destination" else echo "[INFO] Destination folder exists, copy bucket data for ${MAX_AGE}" rclone_command="${rclone_command} --max-age ${MAX_AGE}" fi function replication() { set +o pipefail $rclone_command rook:${bucket} ${BACKUP_BUCKET}:/${BACKUP_BUCKET}/obc-backups/${REGISTRY_NAMESPACE}/${OBJECT_BUCKET_CLAIM}/ -v > /tmp/rcloneout 2> /tmp/rcloneerror return 0 } function error_response(){ return 1 } replication if grep -q 'failed to open source object: NoSuchKey' /tmp/rcloneerror;then echo "[WARN] False positive error with NoSuchKey. Ignore" elif [ -s /tmp/rcloneout ];then echo "[INFO] Replication completed with no errors." else if [ ! -z ${DEBUG} ]; then echo "[ERROR][DEBUG]Debug flag set to true" cat /tmp/rcloneerror else echo "[ERROR]Please run job in debug mode. Add to enviromnet variable DEBUG with value "true" to return logs to stout" fi error_response fi {{- else }} rclone -M -v sync ${BACKUP_BUCKET}:/${BACKUP_BUCKET}/obc-backups/${REGISTRY_NAMESPACE}/${OBJECT_BUCKET_CLAIM} rook:${bucket} {{- end }}Після цього натисніть
SAVE & PUBLISHтаMark as active. Merge Request має виглядати як на зображенні: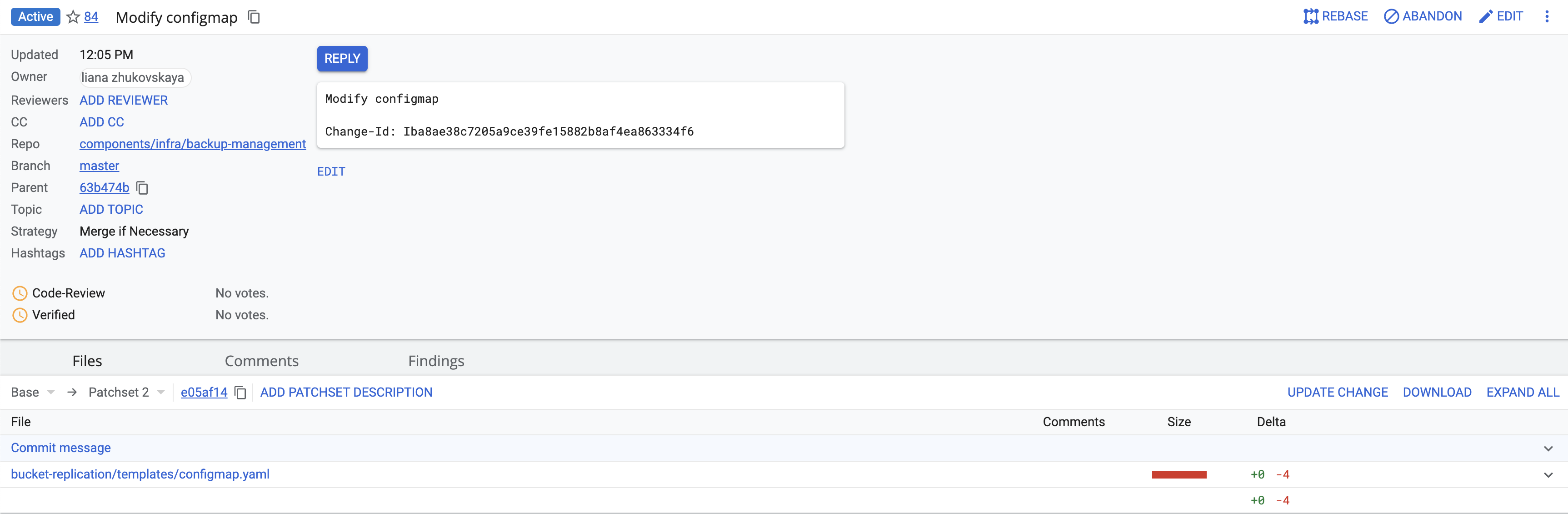
-
Далі натисніть
Reply>Verified +1>Code-Review +2>Submit.
-
5. Оновлення реєстру
Цей крок описує стандартний процес оновлення компонентів реєстру в адміністративній панелі Control Plane.
| Див. детальніше на сторінці Оновлення компонентів реєстру. |
6. Кроки після оновлення реєстру
6.1. Оновлення екземплярів реєстру після його оновлення до версії 1.9.5.
| Розділ стосується лише кластерів, розгорнутих у середовищі AWS. |
Після того, як реєстр було оновлено до версії 1.9.5 та Build-пайплайн пройшов успішно, потрібно оновити інстанси для цього реєстру.
6.1.1. Перевірка полів машин-сету реєстру
Перевірте, що після оновлення реєстру його машин-сет має наступні значення полів ami.id та apiVersion:
-
ami.id:ami-094fe1584439e91dd -
apiVersion:machine.openshift.io/v1beta1
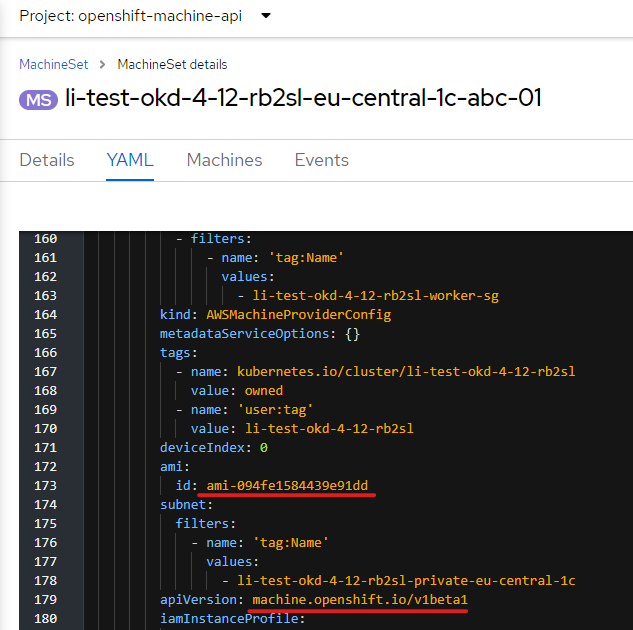
6.1.2. Видалення машин для машин-сету реєстру
Щоби нові поля застосувалися для всіх інстансів машин-сету, потрібно поступово, по одній, видаляти машини поточного машин-сету через інтерфейс OpenShift.
Цей процес потрібно повторити для всіх машин, які належать до машин-сету реєстру.
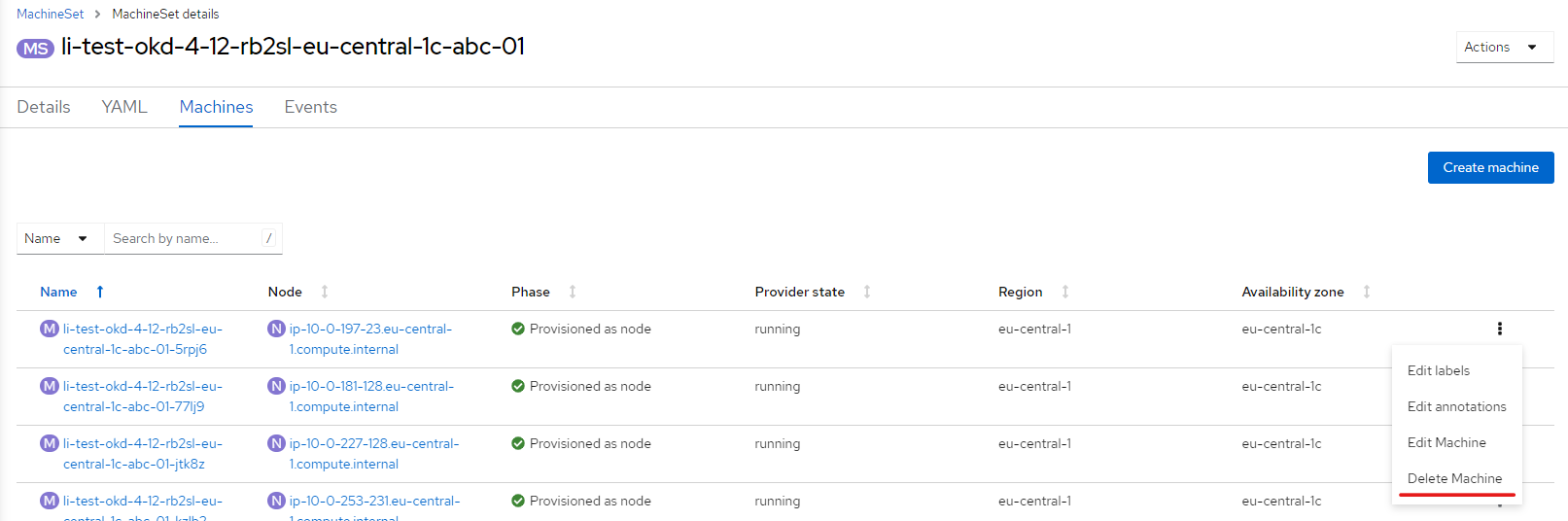
Після видалення машини, нова запуститься автоматично, але вже із новими значеннями полів ami.id та apiVersion.
| Зачекайте, доки запуститься нова машина, і лише після цього переходьте до видалення іншої. |
Після того, як всі машини для машин-сету реєстру перестворені з новими полями ami.id та apiVersion, крок "Оновлення екземплярів реєстру після його оновлення на версію 1.9.5" вважається завершеним.
7. Відомі проблеми
| Проблема | Рішення | ||
|---|---|---|---|
Не працює взаємодія між реєстрами |
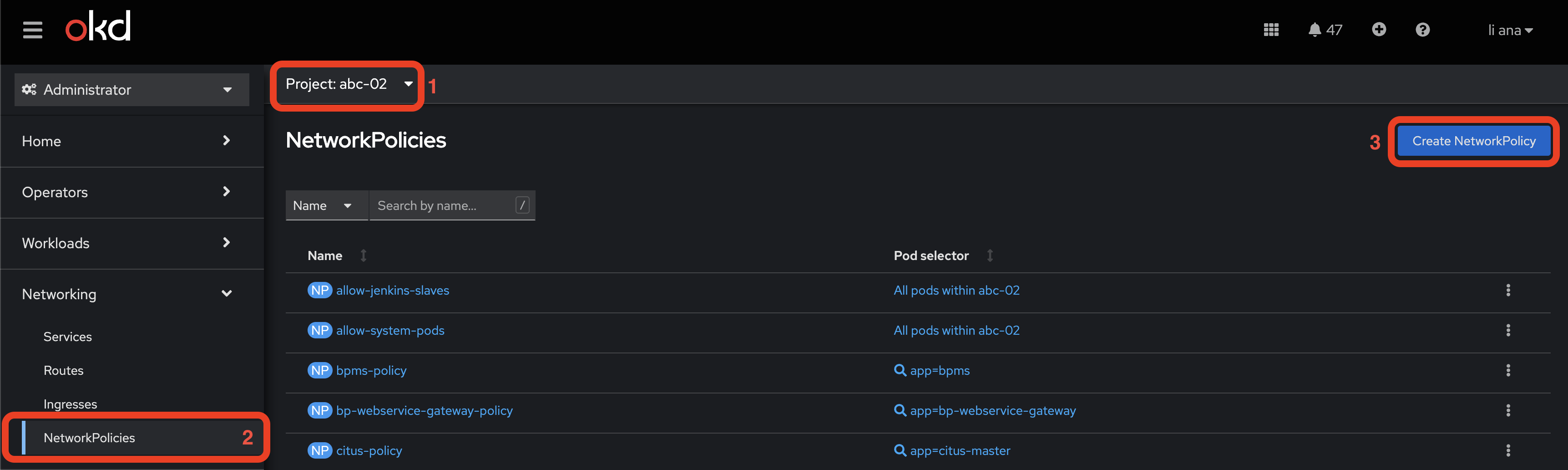
Додавання NetworkPolicy для компонента Для коректної роботи функціональності "ДОСТУП ДЛЯ РЕЄСТРІВ ПЛАТФОРМИ ТА ЗОВНІШНІХ СИСТЕМ", треба перейти в OpenShift-консоль, вибрати потрібний реєстр (1), перейти в NetworkPolicies(2) та створити NetworkPolicy через кнопку
Після цього потрібно замінити текст у текстовому полі на наступний маніфест: platform-gateway-policy.yamlде |
||
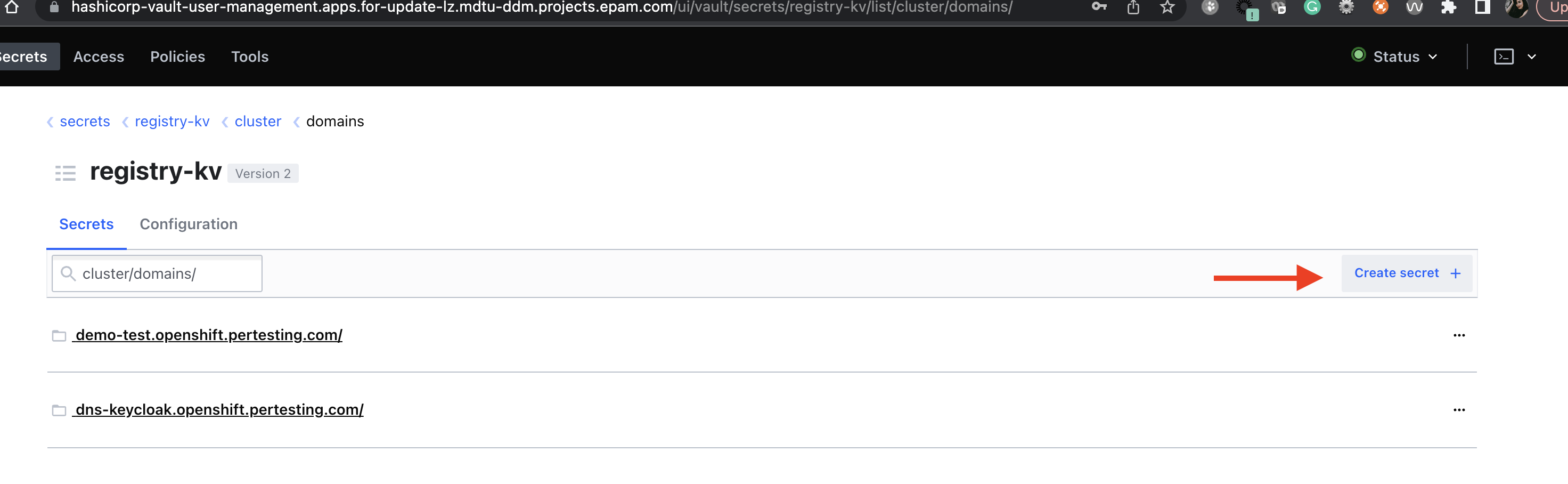
Неможливо додати Keycloak DNS у налаштуваннях Платформи. |
Додайте додатковий DNS на рівні Платформи.
Виконайте наступні кроки:
|
8. Специфічні та нечасті помилки
| Проблема | Рішення |
|---|---|
Після оновлення реєстру до версії |
Повторно розгорніть регламент реєстру для перестворення моделі даних. |
9. Зворотно несумісні зміни
Обов’язково зверніть увагу на важливі зміни у версії 1.9.5 Платформи.
|